Trie

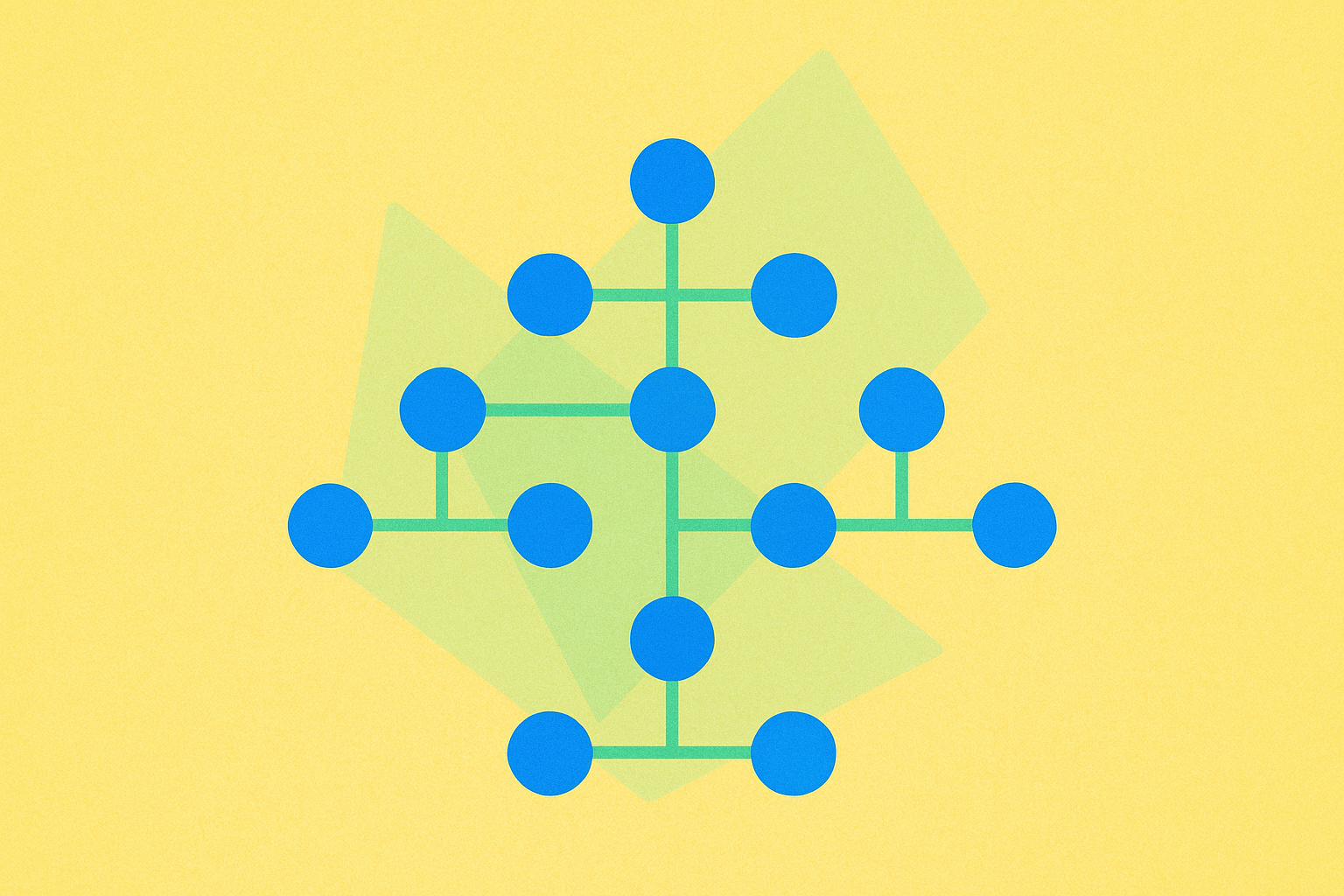
El trie, también denominado árbol de prefijos, es una estructura de búsqueda especializada diseñada para almacenar conjuntos dinámicos o arreglos asociativos en los que las claves suelen ser cadenas de texto. A diferencia de los árboles binarios de búsqueda, los nodos de un trie no contienen la clave asociada directamente. En su lugar, la posición del nodo dentro del árbol determina su clave, lo que lo convierte en una opción especialmente eficiente para operaciones basadas en cadenas.
Los últimos avances en recuperación y almacenamiento de datos han puesto de relieve la importancia estratégica de estructuras como los tries. Un ejemplo es la función de autocompletado de Google, que emplea tries para predecir y mostrar consultas según los primeros caracteres introducidos por el usuario. Esta tecnología mejora la experiencia al proporcionar sugerencias instantáneas y optimiza el proceso de búsqueda al reducir el tiempo y los recursos computacionales necesarios para ofrecer resultados relevantes. La capacidad del trie para compartir prefijos comunes entre cadenas almacenadas lo hace excepcionalmente eficiente en memoria en aplicaciones con grandes vocabularios o volúmenes extensos de cadenas.
Contexto histórico y desarrollo
El trie fue conceptualizado por René de la Briandais en 1959 en un artículo pionero que sentó las bases de esta estructura de datos basada en árboles. El término "trie" lo acuñó Edward Fredkin en 1960, derivado de "retrieval", para destacar su función principal en la recuperación de información. Desde entonces, el trie ha experimentado una evolución significativa, impulsada por su papel esencial en la optimización de búsquedas y el manejo eficiente de grandes conjuntos de datos.
La revolución digital y el crecimiento exponencial de la generación de datos en las últimas décadas han convertido el trie en un componente imprescindible de la infraestructura informática actual. Al gestionar volúmenes masivos de datos textuales, la capacidad única del trie (realizar búsquedas basadas en prefijos en tiempo proporcional a la longitud de la clave y no al número de claves almacenadas) ha ganado relevancia. Así, los tries se han adaptado y optimizado para aplicaciones especializadas, como correctores ortográficos, juegos de palabras, indexación de bases de datos y protocolos de enrutamiento de red.
Aplicaciones en tecnología
Los tries son fundamentales en el desarrollo de software y la tecnología de la información por su estructura singular y eficiente gestión de conjuntos de datos complejos. Sus principales usos se centran en funciones de autocompletado y predicción de texto, presentes en buscadores, teclados móviles y editores, que emplean tries para recorrer posibles completaciones de palabras en tiempo real y aumentar la productividad.
Además del procesamiento de texto, los tries resultan esenciales en algoritmos de enrutamiento IP, donde facilitan la coincidencia rápida de direcciones con sus redes correspondientes. En routers, los tries posibilitan la coincidencia eficiente de prefijos más largos, clave para determinar la ruta óptima de los paquetes en Internet. Su estructura permite realizar búsquedas en tiempo logarítmico respecto a la longitud de la dirección, garantizando una latencia mínima en el reenvío de paquetes.
También son relevantes en bioinformática, donde ayudan a secuenciar y analizar genomas de forma eficiente. Los algoritmos basados en trie permiten buscar rápidamente en grandes volúmenes de datos genéticos, identificar patrones, sub-secuencias y mutaciones. Esta capacidad ha acelerado la investigación en medicina personalizada, biología evolutiva y diagnóstico. Los tries se utilizan además en diccionarios, tablas de símbolos y algoritmos de coincidencia de cadenas fundamentales para los sistemas de procesamiento de texto.
Impacto en el mercado e inversión
La adopción de tries por grandes compañías tecnológicas ha transformado el mercado y el entorno inversor, impulsando el desarrollo de soluciones de software más rápidas y precisas para el procesamiento de datos masivos. Estas mejoras son cruciales en el sector big data, donde la capacidad de recuperar y analizar información rápidamente supone una ventaja competitiva clave.
Las optimizaciones basadas en trie tienen repercusiones económicas que afectan a sectores enteros, más allá de casos individuales. Las organizaciones que integran tries en su infraestructura de datos suelen reducir costes operativos al requerir menos servidores y disminuir los tiempos de respuesta, lo que favorece la satisfacción y retención del cliente. Estos resultados han motivado una fuerte inversión en tecnologías basadas en trie, especialmente en inteligencia artificial y plataformas de machine learning, donde la eficiencia de las estructuras de datos es esencial para el rendimiento de los algoritmos.
La inversión en tecnologías trie ha crecido notablemente en los últimos años, impulsada por la demanda de capacidades avanzadas de procesamiento de datos. El capital riesgo y la inversión corporativa se han volcado en startups y empresas consolidadas que desarrollan sistemas de búsqueda, herramientas de procesamiento de lenguaje natural y soluciones de gestión de bases de datos basadas en tries optimizados. Esta tendencia refleja la consideración de los tries como activos estratégicos determinantes para el liderazgo en industrias intensivas en datos.
Tendencias futuras e innovaciones
El futuro de los tries en tecnología es prometedor, con investigaciones constantes para mejorar su eficiencia, escalabilidad y adaptación a nuevos retos computacionales. Las innovaciones como los tries comprimidos (radix trees o Patricia tries) y los tries de búsqueda ternaria ilustran la evolución continua de esta estructura, que reduce el consumo de memoria y mantiene o mejora el rendimiento en búsquedas, resultando idónea para entornos limitados en recursos y sistemas embebidos.
Con la expansión del Internet de las cosas (IoT) y el avance de la computación en la nube, los tries desempeñarán un papel aún más relevante en la gestión y consulta de los enormes volúmenes de datos generados por estos sistemas. Los dispositivos IoT producen flujos continuos de datos temporales, registros y lecturas de sensores que requieren mecanismos eficientes de indexación y recuperación. Los tries se adaptan perfectamente a la naturaleza jerárquica y orientada a prefijos de muchos formatos de datos IoT, desde identificadores de dispositivos hasta códigos de ubicación geográfica.
Las nuevas aplicaciones en machine learning e inteligencia artificial también impulsan la innovación en tries. Se investiga cómo los tries pueden acelerar operaciones en redes neuronales, especialmente en procesamiento de lenguaje natural, donde la gestión de vocabularios y las búsquedas de embeddings son cuellos de botella. Además, la integración de tries con arquitecturas hardware emergentes, como la memoria no volátil y unidades de procesamiento especializadas, promete alcanzar nuevos niveles de rendimiento. Estos avances pueden suponer una revolución en la gestión y procesamiento de datos, transformando el almacenamiento, la búsqueda y el análisis de información en todos los ámbitos tecnológicos.
Resumen
En definitiva, el trie es una estructura esencial y versátil en la informática actual, con aplicaciones transversales en múltiples industrias y enfocada a mejorar la recuperación de datos y la eficiencia de los sistemas. Su capacidad para procesar grandes volúmenes de datos con claves complejas basadas en cadenas lo hace imprescindible en motores de búsqueda, enrutamiento de red y bioinformática. La propiedad única del trie de compartir prefijos comunes entre claves almacenadas aporta eficiencia de memoria y rapidez en búsquedas, cualidades cada vez más valiosas ante el crecimiento del volumen de datos.
A medida que los datos se incrementan en cantidad y complejidad, la relevancia de los tries crecerá en paralelo, impulsando la innovación tecnológica y la inversión en sectores relacionados. La evolución constante de variantes y optimizaciones confirma la vigencia de esta estructura, concebida hace más de sesenta años. Aunque no siempre se documente explícitamente la implementación de tries en cada plataforma, su uso para mejorar algoritmos de trading, procesamiento de datos financieros y sistemas de análisis en tiempo real es cada vez más habitual. Los principios básicos de los tries (coincidencia eficiente de prefijos, organización jerárquica y recuperación rápida) se alinean con las exigencias de las aplicaciones modernas intensivas en datos, garantizando su relevancia tecnológica en los próximos años.
FAQ
¿Qué es un Trie (árbol de prefijos)? ¿Cuál es su principio básico?
El Trie, también denominado árbol de prefijos o árbol de diccionario, es una estructura de árbol ordenado para almacenar y recuperar cadenas de forma eficiente. Permite compartir prefijos entre cadenas para ahorrar espacio. Cada nodo contiene un carácter y referencias a sus nodos hijos, lo que posibilita búsquedas e inserciones rápidas por prefijo.
¿Cuáles son las ventajas y desventajas del Trie frente a las tablas hash?
El Trie permite búsquedas e inserciones más rápidas en operaciones con cadenas gracias al uso compartido de prefijos, lo que reduce las comparaciones de caracteres. Sin embargo, requiere más memoria, especialmente con claves de longitud variable. Ofrece eficiencia temporal a cambio de mayor consumo de espacio.
¿Cómo se implementa el autocompletado y las sugerencias de búsqueda con Trie?
El Trie emplea una estructura de árbol de prefijos para buscar coincidencias en tiempo O(m), donde m es la longitud de la cadena introducida. Se almacenan los caracteres en los nodos y se marcan los finales de palabra en los nodos hoja, proporcionando autocompletado y sugerencias rápidas.
¿Cuáles son los escenarios de aplicación más habituales del Trie?
El Trie se emplea en autocompletado, corrección y verificación ortográfica, detección y filtrado de palabras sensibles, conteo de prefijos, estadísticas de palabras y consultas binarias eficientes como operaciones XOR máximo.
¿Cómo se implementa una estructura Trie básica?
Se crea una clase de nodo con una tabla hash y una marca para indicar finales de palabra. Se recorren las palabras y se insertan los caracteres secuencialmente en el Trie, compartiendo los prefijos existentes para optimizar el almacenamiento.
¿Cuál es la complejidad temporal y espacial del Trie?
El Trie tiene complejidad temporal O(N) para inserciones y búsquedas, siendo N la longitud de la cadena. La complejidad espacial es O(α^n), donde α es el tamaño del conjunto de caracteres.

Blockchain de forma sencilla: guía para principiantes sobre cómo funciona

Explorando oportunidades profesionales en el desarrollo de blockchain para core developers

Impulsa tu carrera profesional en el desarrollo de Blockchain

Explora una carrera como desarrollador de Blockchain: habilidades y oportunidades
Conceptos básicos de blockchain: funcionamiento

Impulsando el futuro de Web3 en la India: iniciativas comunitarias y educativas

Apalancamiento

Retroceso del mercado cripto

Criptoactivos (moneda virtual) | Una nueva categoría de activos en la era digital

Código diario de cifrado de Hamster Kombat: guía completa y recompensas

Guía diaria de códigos cifrados de Hamster Kombat
