
Trie

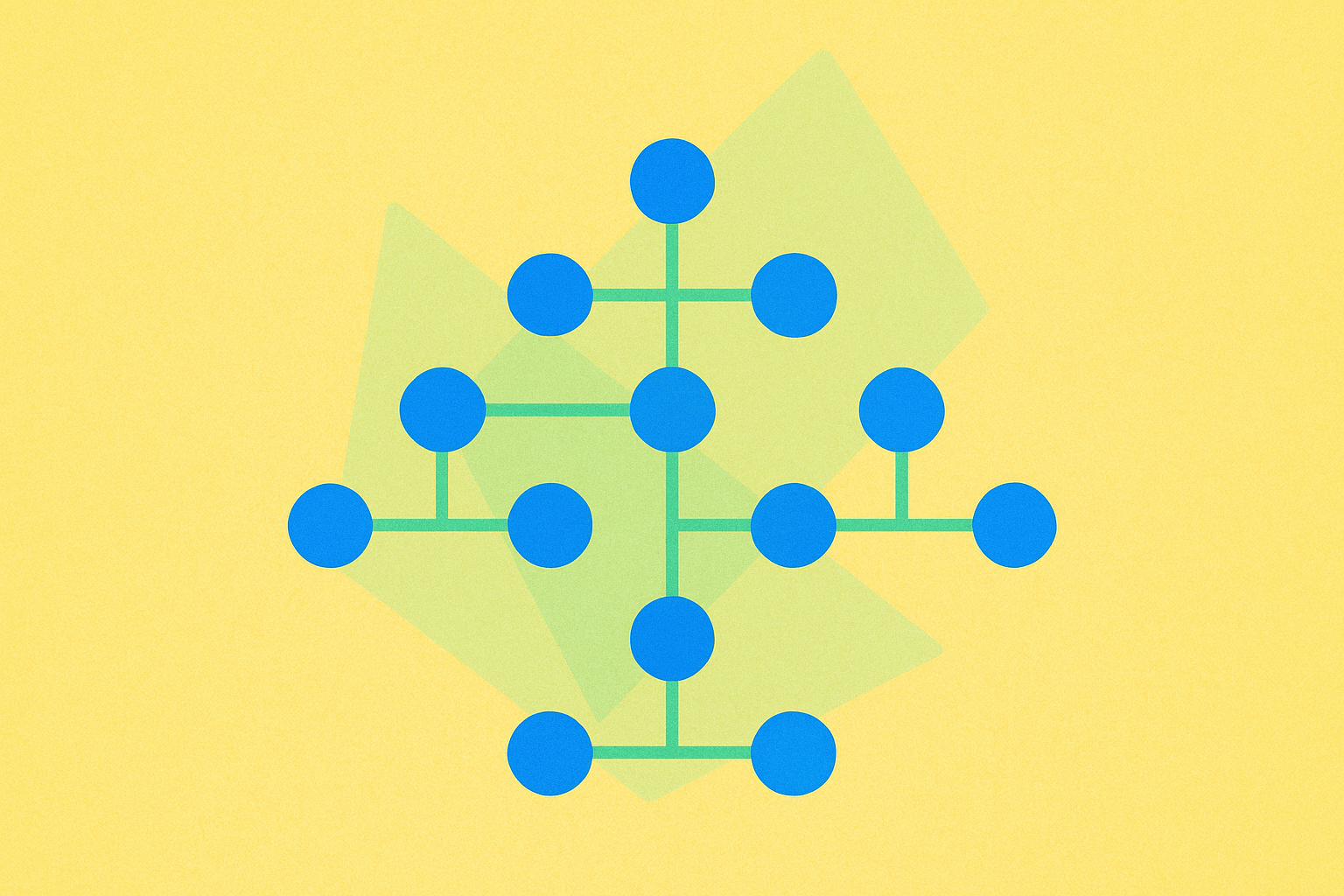
Trie, yang juga dikenal sebagai prefix tree, adalah jenis pohon pencarian khusus yang digunakan untuk menyimpan himpunan dinamis atau array asosiatif di mana kuncinya umumnya berupa string. Berbeda dengan binary search tree, node pada trie tidak secara langsung menyimpan kunci yang terkait pada node tersebut. Sebaliknya, posisi node dalam struktur pohon menentukan kunci yang bersangkutan, sehingga sangat efisien untuk operasi yang berbasis string.
Perkembangan terbaru dalam pengambilan dan penyimpanan data menyoroti pentingnya struktur data yang efisien seperti trie. Contohnya, fitur autocomplete Google memanfaatkan struktur data trie untuk memprediksi dan menampilkan kueri pencarian berdasarkan karakter awal yang dimasukkan pengguna. Implementasi ini tidak hanya meningkatkan pengalaman pengguna dengan memberikan saran secara instan, tetapi juga mengoptimalkan proses pencarian dengan mengurangi waktu dan sumber daya komputasi yang dibutuhkan untuk menghasilkan hasil yang relevan. Kemampuan trie untuk berbagi prefix umum antar string yang disimpan menjadikannya sangat efisien secara memori untuk aplikasi yang menangani kosakata besar atau dataset string yang sangat luas.
Konteks Historis dan Perkembangan
Konsep trie pertama kali diperkenalkan dalam makalah terobosan tahun 1959 oleh ilmuwan komputer Prancis René de la Briandais, yang mengenalkan prinsip dasar dari struktur data berbasis pohon ini. Istilah "trie" sendiri kemudian diciptakan oleh Edward Fredkin pada tahun 1960, diambil dari kata "retrieval" untuk menekankan tujuan utamanya dalam operasi pemulihan data. Sejak awal, trie telah mengalami evolusi signifikan, terutama karena peran pentingnya dalam mengoptimalkan pencarian dan penanganan dataset skala besar secara efisien.
Revolusi digital serta pertumbuhan eksponensial dalam produksi data selama beberapa dekade terakhir telah mengubah trie dari sekadar topik akademik menjadi komponen vital dalam infrastruktur komputasi modern. Ketika organisasi mulai menangani volume data tekstual yang sangat besar, sifat khas trie—khususnya kemampuannya melakukan pencarian berbasis prefix dalam waktu yang proporsional terhadap panjang kunci pencarian, bukan jumlah kunci yang disimpan—menjadi sangat bernilai. Trie pun telah diadaptasi dan dioptimalkan untuk berbagai aplikasi khusus, mulai dari pemeriksa ejaan dan permainan kata hingga pengindeksan basis data dan protokol routing jaringan.
Aplikasi dalam Teknologi
Trie banyak digunakan dalam pengembangan perangkat lunak dan teknologi informasi karena strukturnya yang unik dan efisiensinya dalam menangani dataset yang kompleks. Salah satu aplikasi utamanya adalah pada fitur autocomplete dan prediksi teks yang banyak ditemukan di mesin pencari, keyboard ponsel, dan editor teks modern. Sistem-sistem ini memanfaatkan trie untuk menelusuri kemungkinan penyelesaian kata berdasarkan input pengguna secara cepat, menawarkan saran waktu nyata yang meningkatkan produktivitas.
Selain pemrosesan teks, trie juga berperan penting dalam implementasi algoritma routing IP, di mana strukturnya memungkinkan pencocokan cepat alamat IP ke jaringan yang relevan. Pada router jaringan, trie memfasilitasi pencocokan prefix terpanjang secara efisien, yang esensial untuk menentukan jalur optimal paket data di internet. Struktur ini memungkinkan router melakukan pencarian dalam waktu logaritmik terhadap panjang alamat, sehingga memastikan latensi minimum dalam forwarding paket.
Bidang aplikasi penting lainnya adalah bioinformatika, di mana trie digunakan untuk sekuestrasi dan analisis genom secara efisien. Peneliti memanfaatkan algoritma berbasis trie untuk menelusuri dataset genetik berskala besar, mengidentifikasi pola, subsekuensi, dan mutasi. Kemampuan melakukan pencarian urutan DNA secara cepat dalam basis data genomik yang sangat besar telah mempercepat penelitian di bidang pengobatan personal, biologi evolusi, dan diagnosis penyakit. Selain itu, trie digunakan dalam implementasi kamus, tabel simbol, dan beragam algoritma pencocokan string yang menjadi fondasi sistem pemrosesan teks.
Dampak Pasar dan Investasi
Penerapan struktur data trie oleh perusahaan teknologi terkemuka telah memberikan dampak besar pada pasar teknologi dan lanskap investasi secara keseluruhan. Implementasi ini mendorong pengembangan solusi perangkat lunak yang lebih cepat dan efisien, mampu memproses data dalam jumlah besar dengan kecepatan dan akurasi yang lebih tinggi dibandingkan sebelumnya. Peningkatan efisiensi ini sangat penting bagi perusahaan di sektor big data, di mana kemampuan mengambil dan menganalisis data secara cepat menjadi keunggulan kompetitif utama di pasar berbasis teknologi.
Dampak ekonomi dari optimasi berbasis trie meluas hingga ke seluruh sektor industri. Organisasi yang berhasil memanfaatkan trie dalam infrastruktur datanya kerap mengalami penurunan biaya operasional melalui pengurangan kebutuhan server dan waktu respons yang lebih singkat, yang berdampak pada peningkatan kepuasan serta retensi pelanggan. Manfaat nyata ini menarik minat investasi besar pada teknologi yang mengadopsi trie, terutama di platform artificial intelligence dan machine learning, di mana struktur data efisien sangat krusial untuk performa algoritma.
Investasi pada teknologi berbasis trie tumbuh pesat dalam beberapa tahun terakhir, didorong oleh permintaan yang meningkat terhadap kemampuan pemrosesan data yang lebih canggih. Modal ventura dan investasi korporasi mengalir ke startup maupun perusahaan mapan yang mengembangkan sistem pencarian mutakhir, alat natural language processing, dan solusi manajemen basis data yang mengandalkan implementasi trie yang dioptimalkan. Tren investasi ini menandakan pemahaman bahwa struktur data efisien seperti trie merupakan aset strategis yang dapat menentukan kepemimpinan pasar di era data besar.
Tren dan Inovasi Masa Depan
Masa depan trie di dunia teknologi sangat menjanjikan, dengan riset yang terus berlanjut untuk meningkatkan efisiensi, skalabilitas, dan adaptasinya terhadap tantangan komputasi baru. Inovasi seperti compressed trie (juga dikenal sebagai radix tree atau Patricia trie) dan ternary search trie merupakan contoh evolusi struktur data fundamental ini untuk menjawab tuntutan komputasi modern. Varian-varian tersebut dapat mengurangi konsumsi memori sambil mempertahankan atau bahkan meningkatkan kinerja pencarian, sehingga cocok untuk sistem dengan keterbatasan memori dan perangkat embedded.
Seiring pertumbuhan Internet of Things (IoT) dan semakin canggihnya komputasi awan, trie diprediksi memainkan peran semakin penting dalam pengelolaan dan pencarian data dalam jumlah besar yang dihasilkan teknologi tersebut. Perangkat IoT menghasilkan data time-series, log, dan pembacaan sensor secara kontinu yang memerlukan mekanisme pengindeksan serta pengambilan data yang efisien. Struktur berbasis trie sangat ideal untuk menangani format data IoT yang bersifat hierarkis dan berbasis prefix, mulai dari pengenal perangkat hingga kode lokasi geografis.
Inovasi dalam machine learning dan artificial intelligence juga terus mendorong pengembangan trie. Peneliti mengeksplorasi bagaimana trie dapat mempercepat proses neural network, khususnya dalam natural language processing di mana manajemen kosakata dan pencarian word embedding sering menjadi hambatan kinerja. Selain itu, integrasi trie dengan arsitektur perangkat keras mutakhir seperti memori non-volatile dan unit pemrosesan khusus menjanjikan lompatan performa baru. Perkembangan ini dapat membawa terobosan dalam teknologi penanganan serta pemrosesan data, berpotensi merevolusi cara kita menyimpan, mencari, dan menganalisis informasi lintas berbagai aplikasi.
Ringkasan
Singkatnya, struktur data trie adalah alat yang sangat kuat dan fleksibel dalam komputasi modern, dengan aplikasi luas di banyak industri untuk meningkatkan proses pengambilan data dan efisiensi sistem. Kemampuan trie dalam memproses dataset besar dengan kunci string yang kompleks membuatnya sangat penting di bidang seperti search engine, routing jaringan, dan bioinformatika. Sifat unik trie yang memungkinkan berbagi prefix umum di antara kunci-kunci yang disimpan memberikan efisiensi memori dan pencarian yang sangat cepat—karakteristik yang makin bernilai seiring pertumbuhan volume data.
Seiring data terus bertambah baik dalam volume maupun kompleksitas, peran trie diperkirakan akan semakin besar, mendorong perkembangan teknologi dan investasi di sektor terkait. Evolusi varian dan optimasi trie yang terus berlangsung membuktikan relevansi abadi struktur data ini sejak lebih dari enam dekade lalu. Walau implementasi trie pada platform tertentu tidak selalu terdokumentasi secara eksplisit, penggunaannya dalam meningkatkan algoritma trading, pemrosesan data keuangan, dan sistem analitik real-time sangat mungkin dan kian umum. Prinsip dasar trie—pencocokan prefix yang efisien, organisasi hierarkis, serta pengambilan data yang cepat—sangat selaras dengan kebutuhan aplikasi data-intensif masa kini, memastikan trie tetap penting dalam lanskap teknologi di masa mendatang.
FAQ
Apa itu Trie (Prefix Tree)? Apa prinsip dasarnya?
Trie, juga dikenal sebagai prefix tree atau pohon kamus, adalah struktur pohon terurut yang memungkinkan penyimpanan dan pengambilan string secara efisien. Struktur ini membagi prefix yang sama antar string untuk menghemat ruang penyimpanan. Setiap node berisi karakter dan referensi ke node anak, sehingga pencarian dan penyisipan berbasis prefix menjadi sangat cepat.
Apa kelebihan dan kekurangan Trie dibandingkan Hash table?
Trie memberikan kecepatan kueri dan penyisipan lebih tinggi untuk operasi string melalui pembagian prefix sehingga mengurangi perbandingan karakter. Namun, trie memerlukan lebih banyak memori, terutama jika kunci bervariasi panjangnya. Struktur ini mengorbankan efisiensi ruang demi efisiensi waktu.
Bagaimana mengimplementasikan autocomplete dan saran pencarian menggunakan Trie?
Trie memanfaatkan struktur prefix tree untuk mencocokkan prefix dengan kompleksitas waktu O(m), di mana m adalah panjang string input. Simpan karakter pada node, tandai akhir kata pada node daun, sehingga autocomplete dan saran pencarian bisa dilakukan secara efisien.
Apa saja skenario aplikasi umum Trie dalam praktik?
Trie banyak digunakan untuk autocomplete, pemeriksaan dan koreksi ejaan, pendeteksian dan penyaringan kata sensitif, penghitungan prefix, statistik kata, serta kueri biner efisien seperti operasi maksimum XOR.
Bagaimana mengimplementasikan struktur data Trie dasar?
Buat kelas node dengan hash table dan penanda akhir kata. Iterasi setiap kata dan sisipkan karakter secara berurutan ke dalam Trie. Bagikan prefix yang sudah ada untuk mengoptimalkan ruang penyimpanan.
Berapa kompleksitas waktu dan ruang Trie?
Trie memiliki kompleksitas waktu O(N) untuk operasi penyisipan dan pencarian, di mana N adalah panjang string. Kompleksitas ruangnya O(α^n), di mana α adalah ukuran himpunan karakter.

Blockchain Mudah Dipahami: Panduan Pemula Mengenai Cara Kerja Blockchain

Menelusuri Peluang Karier di Pengembangan Blockchain bagi Core Developer

Menjelajahi Karier sebagai Blockchain Developer: Keterampilan dan Peluang

Mulai Karier Anda di Pengembangan Blockchain
Dasar-Dasar Blockchain: Cara Kerjanya

Mendorong Masa Depan Web3 India: Inisiatif Komunitas dan Edukasi

Di Mana Anda Dapat Membeli Pi Coin? Panduan Lengkap

Apa Dompet Solana Terbaik?

Panduan Bermain dan Mendapatkan Kripto untuk Pemula

Apakah CoinGecko Sah?

Cara Mendapatkan Kode Undangan Pi Network
