Дерево Trie

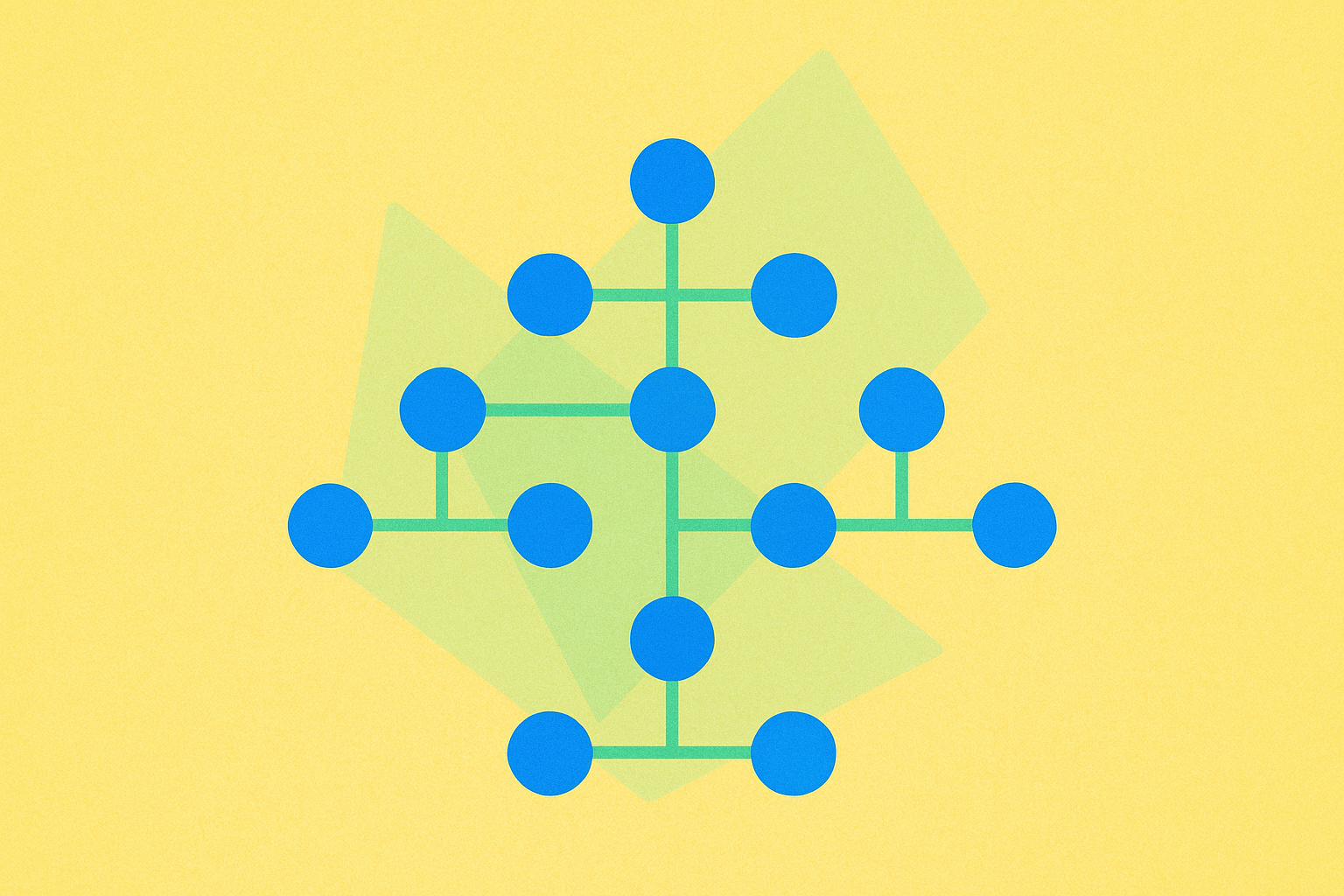
Trie, или префиксное дерево, представляет собой специализированный вид дерева поиска, используемого для хранения динамических множеств или ассоциативных массивов, где ключами обычно выступают строки. В отличие от бинарных деревьев поиска, узлы в trie не содержат непосредственно ключ, связанный с этим узлом. Ключ определяется положением узла внутри дерева, что делает такую структуру особенно эффективной для операций со строками.
Последние достижения в области поиска и хранения данных подчеркнули важность эффективных структур данных, таких как trie. Например, функция автодополнения Google использует структуры trie для прогнозирования и отображения поисковых запросов на основе начальных символов, введённых пользователем. Такая реализация не только улучшает пользовательский опыт за счёт мгновенных подсказок, но и оптимизирует процесс поиска, сокращая время и вычислительные ресурсы, необходимые для выдачи релевантных результатов. Благодаря возможности trie хранить общие префиксы для разных строк, структура становится особенно экономичной по памяти при работе с большими словарями или масштабными наборами строк.
Исторический контекст и развитие
Понятие trie впервые было описано в 1959 году французским учёным в области информатики Рене де ла Брианде, который сформулировал базовые принципы этой структуры данных на основе дерева. Термин «trie» был предложен в 1960 году Эдвардом Фредкиным и образован от слова «retrieval» — чтобы подчеркнуть основное назначение структуры в операциях поиска данных. С момента появления trie претерпело значительную эволюцию, главным образом благодаря своей ключевой роли в оптимизации поисковых запросов и эффективной работе с крупными наборами данных.
Цифровая революция и экспоненциальный рост объёмов генерируемых данных за последние десятилетия превратили trie из академической новинки в неотъемлемую часть современной вычислительной инфраструктуры. По мере того как организации стали работать с огромными объёмами текстовой информации, уникальные свойства trie — в частности, выполнение поиска по префиксу за время, пропорциональное длине ключа, а не количеству хранимых ключей — приобрели особую ценность. В результате trie было адаптировано и оптимизировано для различных специализированных применений: от проверки орфографии и словесных игр до индексирования в базах данных и протоколов маршрутизации в сетях.
Применение в технологиях
Trie широко применяется в разработке программного обеспечения и информационных технологиях благодаря уникальной структуре и высокой эффективности при работе со сложными наборами данных. Одно из основных направлений использования — функции автодополнения и текстового прогнозирования, которые сегодня присутствуют в поисковых системах, мобильных клавиатурах и текстовых редакторах. Эти системы используют trie для быстрой проверки возможных вариантов слов на основе ввода пользователя, обеспечивая мгновенные подсказки и повышая производительность работы.
Вне текстовой обработки trie играет важную роль в реализации алгоритмов маршрутизации IP, где обеспечивает быстрое сопоставление IP-адресов с соответствующими сетями. В сетевых маршрутизаторах trie позволяет эффективно выполнять поиск по наиболее длинному префиксу, что лежит в основе определения оптимального пути передачи данных по интернету. Такая структура даёт возможность выполнять поиск за логарифмическое время относительно длины адреса, что минимизирует задержки при пересылке пакетов.
Ещё одна важная область применения — биоинформатика, где trie используется для эффективного секвенирования и анализа генома. Исследователи применяют алгоритмы на основе trie для быстрого поиска по огромным объёмам генетических данных, выявления паттернов, подпоследовательностей и мутаций. Быстрый поиск конкретных последовательностей ДНК в масштабных геномных базах ускорил развитие персонализированной медицины, эволюционной биологии и диагностики заболеваний. Кроме того, trie используется при реализации словарей, таблиц символов и различных алгоритмов поиска подстрок, которые лежат в основе систем обработки текста.
Влияние на рынок и инвестиции
Внедрение структур данных trie крупными технологическими компаниями оказало глубокое влияние на рынок технологий и инвестиционный ландшафт. Массовое применение привело к созданию более быстрых и эффективных программных решений, способных обрабатывать огромные объёмы данных с большей скоростью и точностью, чем это было возможно ранее. Такие улучшения особенно важны для компаний, работающих с большими данными, где скорость поиска и анализа информации обеспечивает значительное конкурентное преимущество на технологических рынках.
Экономический эффект от оптимизаций на основе trie распространяется не только на отдельные компании, но и на целые отрасли. Организации, эффективно использующие trie в своей инфраструктуре данных, получают снижение операционных затрат за счёт уменьшения требований к серверам и сокращения времени отклика, что приводит к росту удовлетворённости и лояльности клиентов. Эти реальные преимущества привели к росту инвестиционного интереса к технологиям, использующим trie, особенно в сферах искусственного интеллекта и машинного обучения, где эффективные структуры данных критичны для производительности алгоритмов.
Инвестиции в технологии на основе trie значительно возросли в последние годы на фоне растущего спроса на более совершенные средства обработки данных. Венчурные и корпоративные инвестиции направляются в стартапы и крупные компании, разрабатывающие продвинутые поисковые системы, инструменты обработки естественного языка и системы управления базами данных, основанные на оптимизированных реализациях trie. Эта тенденция отражает понимание того, что эффективные структуры данных — такие как trie — являются не просто техническими деталями, а стратегическим активом, способным определять лидерство на рынках, ориентированных на работу с большими данными.
Будущие тенденции и инновации
Будущее trie в технологиях выглядит крайне перспективно: продолжаются исследования по повышению эффективности, масштабируемости и применимости структуры к новым вычислительным задачам. Инновации, такие как сжатые trie (radix trees или Patricia tries) и трёхзначные деревья поиска, демонстрируют, что базовая структура данных продолжает эволюционировать в ответ на современные требования. Эти варианты уменьшают потребление памяти при сохранении или даже увеличении скорости поиска, что делает их пригодными для встраиваемых и ресурсоограниченных систем.
По мере развития Интернета вещей (IoT) и усложнения облачных вычислений роль trie в управлении и обработке огромных объёмов данных будет только расти. Устройства IoT формируют непрерывные потоки временных рядов, журналов и показаний датчиков, требующие эффективных механизмов индексирования и поиска. Trie хорошо подходят для иерархичных и основанных на префиксе форматов IoT-данных — от идентификаторов устройств до географических кодов.
Инновации в области машинного обучения и искусственного интеллекта также способствуют развитию trie. Исследователи изучают возможности ускорения нейросетевых операций с помощью trie, особенно для задач обработки естественного языка, где управление словарём и поиск эмбеддингов часто становятся узким местом производительности. Кроме того, интеграция trie с новыми аппаратными архитектурами — такими как энергонезависимая память и специализированные вычислительные устройства — обещает вывести производительность на новый уровень. Эти разработки могут привести к прорывным инновациям в технологиях обработки и хранения данных, радикально изменив способы поиска, хранения и анализа информации в самых разных сферах применения.
Итоги
Таким образом, структура данных trie — это мощный и универсальный инструмент современной вычислительной индустрии с широкими возможностями применения в различных отраслях для повышения эффективности поиска и обработки данных. Способность эффективно работать с большими наборами строковых ключей делает trie незаменимым в поисковых системах, сетевой маршрутизации и биоинформатике. Уникальное свойство trie — объединение общих префиксов у хранимых ключей — обеспечивает экономию памяти и высокую скорость поиска, что становится всё более важным по мере роста объёмов данных.
По мере увеличения объёмов и усложнения данных значение trie будет только расти, способствуя дальнейшему развитию технологий и инвестиций в соответствующие сектора. Эволюция вариантов и оптимизаций trie доказывает неизменную актуальность этой структуры данных, впервые предложенной более шестидесяти лет назад. Хотя конкретные реализации trie на отдельных платформах часто не документируются явно, их использование для улучшения торговых алгоритмов, финансовой обработки данных и систем аналитики в реальном времени весьма вероятно и становится всё более распространённым. Базовые принципы работы trie — эффективное сопоставление префиксов, иерархическая организация и быстрый поиск — полностью соответствуют требованиям современных приложений, работающих с большими объёмами данных, что гарантирует востребованность структуры в технологической сфере на долгие годы.
FAQ
Что такое Trie (префиксное дерево)? *| **|** *|**|**|**|**|*|*|**|*|*|*|(*|*|*|*|*|*|*|*|*|*|*|*|*|*|*|*|*|*|*|*|*| *| *| *| *|*| *| *|*|*| *| *| *| *|*| *| *|*| *|*| *| *| *| *|*| *| *| *| *|*| *| *| *| *|*| *| *| *| *|*| *| *| *| *|*| *| *| *| *|*| *| *| *| *|*| *| *| *| *|*| *| *| *| *|*| *| *| *| *|*| *| *| *| *|*| *| *| *| *|*| *| *| *| *|*| *| *| *| *|*| *| *| *| *|*| *| *| *| *|*| *| *| *| *|*| *| *| *| *|*| *| *| *| *|*| *| *| *| *|*| *| *| *| *|*| *| *| *| *|*| *| *| *| *|*| *| *| *| *|*| *| *| *| *|*| *| *| *| *|*| *| *| *| *|*| *| *| *| *|*| *| *| *| *|*| *| *| *| *|*| *| *| *| *|*| *| *| *| *|*| *| *| *| *|*| *| *| *| *|*| *| *| *| *|*| *| *| *| *|*| *| *| *| *|*| *| *| *| *|*| *| *| *| *|*| *| *| *| https: *| *| *| *|*| https: *| *| *| *|*| *| *| *| *|*| https://www.nist.gov *| *| *| *|*| *| *| *| *|*| https://www.https://www ~|*|*|*|*|*|*|*|*|*|*|*|*|*|*|*|*|*|*|*|*|*|*|*|*|*|*|*|*|*|*|*|*|*|*|*|*|*|*|*|*|*|*|*|*|*|*|*|*|*|*|*|*|*|*|*|*|*|*|*|*|*|*|*|*|*|*| *| *|*| *|*| *| *|*|*| *| *| |*| *|*| *|*| \|*| |*| |*| |*| |*| |*| |*| |*| |*| |*| |*| |*| |*| |*| |*| |*| |*| |*| |*| |*| |*| |*| |*| |*| |*| |*| |*| |*| |*| |*| | *| *| |*| *| |*| |*| |*| |*| |*| *| *| |*| *| *| |*| |*| |*| |*| |*| |*| |*| |*| |*| |*| |*| |*|\ ^| *| ~| |*| |*| |*| |*| |*| |*| |*| |*| *| *| |*| *| |*| |*| |*| |*| |*| |*| |*| |*| |*| |*| |*\ |*| *| *| |*| |*| |*| |*| *| *| |*| \ https:* Информация не предназначена и не является финансовым советом или любой другой рекомендацией любого рода, предложенной или одобренной Gate.

Простое руководство по блокчейн: как он работает для новичков

Карьерные перспективы для Core Developers в области разработки блокчейн

Начните профессиональный путь в сфере разработки блокчейн-технологий

Построение карьеры блокчейн-разработчика: необходимые навыки и перспективы
Основы блокчейна: как работает технология

Развитие Web3 в Индии: инициативы поддержки сообщества и образовательные программы

Децентрализованный кошелек и акция Zebec Trading and Holding с общим призовым фондом $3 000 в ZBC

Руководство по получению форк-токенов: Как добавить пользовательский токен?

Всё, что необходимо знать о DePIN

Предстоящий airdrop Notcoin: ключевая информация

Крипто Red Packet: отправка и получение цифровых подарков
