Дерево Trie

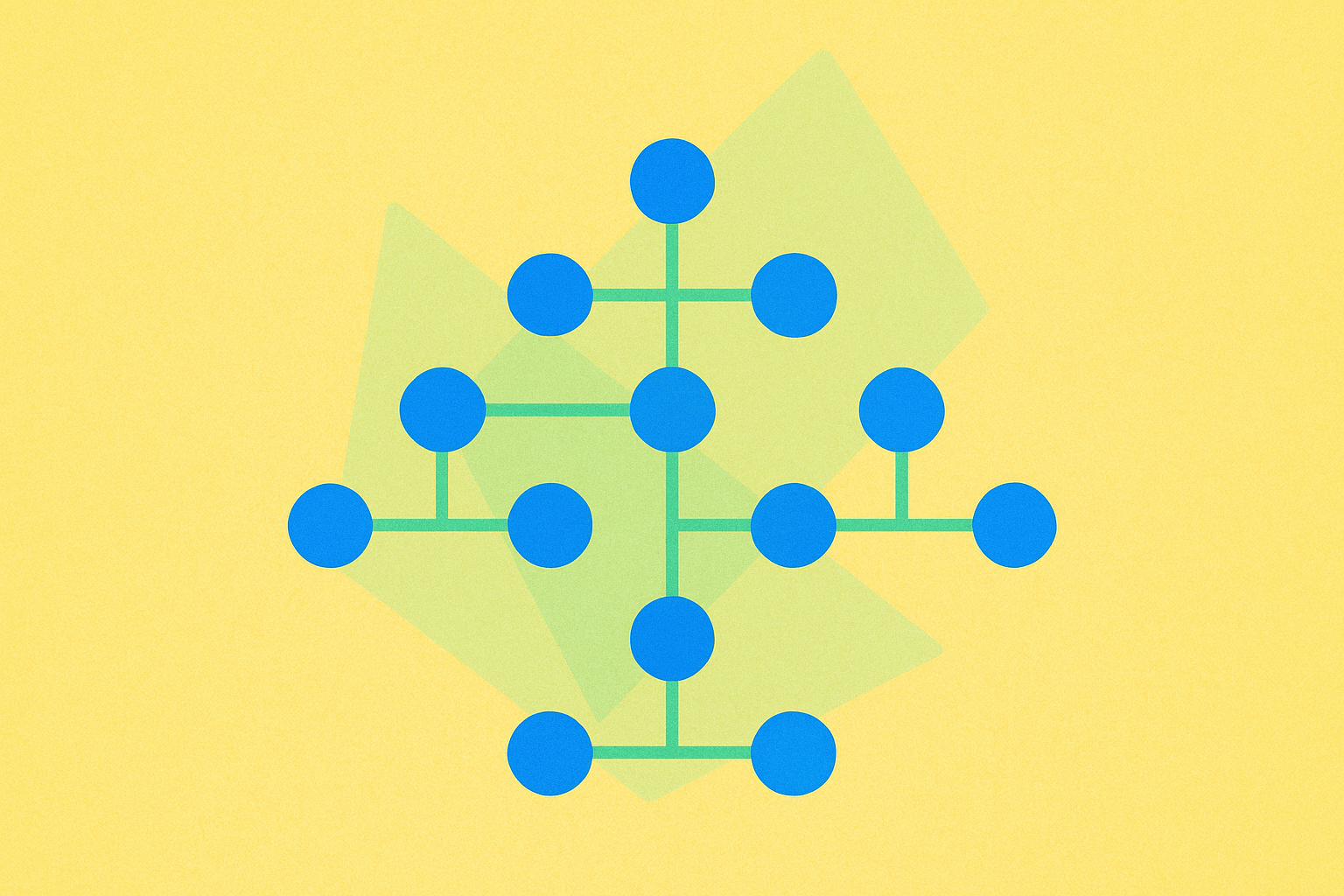
Trie, або префіксне дерево, — це спеціалізована структура для зберігання динамічних множин або асоціативних масивів, де ключі представлено рядками. На відміну від бінарних дерев пошуку, вузли Trie не містять ключі безпосередньо. Ключ визначає розташування вузла у дереві. Trie відзначається особливою ефективністю для операцій із рядками.
Останні досягнення у сфері отримання та зберігання даних підкреслюють важливість ефективних структур даних, таких як Trie. Наприклад, функція автозаповнення Google використовує Trie для прогнозування та відображення пошукових запитів на основі введених користувачем символів. Ця реалізація підвищує зручність користування завдяки миттєвим підказкам, а також оптимізує пошук, скорочуючи час і ресурси для отримання результатів. Trie забезпечує спільне використання префіксів між рядками, що дає значну економію пам’яті у застосунках із великими словниками чи наборами рядків.
Історичний контекст і розвиток
Концепцію Trie вперше описав у 1959 році французький інформатик Рене де ла Бріанда, який сформулював основні принципи цієї деревної структури. Термін «trie» запровадив Едвард Фредкін у 1960 році, утворивши його від англійського слова «retrieval», щоб підкреслити призначення для отримання даних. Trie еволюціонував завдяки своїй ролі в оптимізації пошукових запитів і ефективній обробці великих наборів даних.
Цифрова революція та стрімке зростання обсягів даних перетворили Trie з академічної концепції на незамінний елемент сучасної IT-інфраструктури. При зростанні обсягу текстових даних у компаній унікальні властивості Trie — зокрема, пошук за префіксом із часом, пропорційним довжині ключа, а не їхній кількості — набули особливої ваги. Trie адаптували для різних спеціалізованих застосувань: перевірки правопису, словникових ігор, індексації баз даних та мережевої маршрутизації.
Застосування у технологіях
Trie активно використовують у розробці програмного забезпечення та ІТ завдяки структурі та ефективності при роботі зі складними наборами даних. Основні сфери застосування — автозаповнення й прогноз тексту, які є стандартом у пошукових системах, клавіатурах і текстових редакторах. Системи на базі Trie швидко перебирають можливі слова відповідно до введення користувача, пропонуючи підказки в реальному часі.
Окрім текстової обробки, Trie застосовують у маршрутизації IP-адрес, забезпечуючи швидке зіставлення адрес з відповідними мережами. У маршрутизаторах Trie дозволяє ефективно знаходити найдовший префікс, що є основою вибору оптимального маршруту для пакетів даних. Структура дає змогу здійснювати ці пошуки з логарифмічною складністю щодо довжини адреси, забезпечуючи мінімальні затримки при пересиланні пакетів.
Важливе застосування Trie має і в біоінформатиці, де його використовують для ефективного аналізу та секвенування геномів. Дослідники швидко шукають у великих масивах генетичної інформації, виявляючи патерни, підпослідовності та мутації. Trie пришвидшує пошук конкретних ДНК-послідовностей у геномних базах, що прискорює дослідження персоналізованої медицини, еволюційної біології та діагностики хвороб. Trie також використовують у словниках, таблицях символів та алгоритмах пошуку рядків, які є основою систем обробки тексту.
Вплив на ринок і інвестиції
Впровадження Trie провідними технологічними компаніями значно вплинуло на ринок IT і інвестиційний ландшафт. Широке застосування сприяло створенню швидших і ефективніших програмних рішень для обробки великих масивів даних із більшою точністю та швидкістю. Ефективність особливо важлива для компаній у сфері Big Data, де швидкий пошук і аналіз інформації забезпечують конкурентну перевагу.
Економічні переваги Trie виходять за межі окремих компаній і охоплюють цілі галузі. Організації, що ефективно використовують Trie у своїй інфраструктурі даних, знижують витрати на сервери та час відгуку, підвищуючи задоволеність клієнтів. Це стимулює інвестиції у технології на базі Trie, особливо в платформах штучного інтелекту та машинного навчання, де ефективні структури даних впливають на продуктивність алгоритмів.
Інвестиції в Trie-технології зростають завдяки попиту на більш складні системи обробки даних. Венчурний та корпоративний капітал спрямовується у стартапи і компанії, які розробляють передові пошукові системи, інструменти обробки природної мови та рішення для управління базами даних, що залежать від оптимізованих реалізацій Trie. Ця динаміка свідчить про розуміння того, що ефективні структури даних — це стратегічний актив для лідерства на ринку у сферах з великими обсягами даних.
Майбутні тенденції та інновації
Майбутнє Trie у технологіях виглядає перспективно: тривають дослідження щодо підвищення ефективності, масштабованості та застосування до нових обчислювальних задач. Такі інновації, як стиснуті Trie (radix tree або Patricia trie) та тернарні пошукові Trie, демонструють розвиток базової структури відповідно до сучасних вимог. Вони скорочують використання пам’яті, зберігаючи або покращуючи швидкість пошуку, що підходить для систем із обмеженими ресурсами та вбудованих пристроїв.
Зі зростанням Інтернету речей (IoT) і розвитку хмарних обчислень роль Trie у керуванні й пошуку даних, які генерують ці технології, буде ще вагомішою. IoT-пристрої створюють потоки даних, журнальні записи та показники, що потребують ефективної індексації та пошуку. Trie добре підходить для обробки ієрархічних і префіксних форматів IoT-даних — від ідентифікаторів пристроїв до геолокаційних кодів.
Застосування Trie у машинному навчанні та штучному інтелекті також розширюється. Дослідники вивчають можливості використання Trie для пришвидшення операцій нейронних мереж, особливо у задачах обробки природної мови, де пошук слів і векторних подань є вузьким місцем продуктивності. Інтеграція Trie з новою апаратною архітектурою, зокрема енергонезалежною пам’яттю та спеціалізованими процесорними блоками, відкриває нові рівні продуктивності. Це може призвести до інновацій у технологіях обробки даних, змінюючи підходи до зберігання, пошуку й аналізу інформації у різних сферах.
Підсумок
Trie — це потужна та універсальна структура даних для сучасних обчислень, яка широко використовується для підвищення ефективності пошуку і обробки даних у багатьох галузях. Trie ефективно працює з великими наборами та складними рядковими ключами, тому є необхідною для пошукових систем, мережевої маршрутизації, біоінформатики. Унікальна властивість Trie — спільне використання префіксів між ключами — забезпечує економію пам’яті і швидкий пошук, що особливо важливо при зростанні обсягів даних.
Зі збільшенням обсягів і складності даних значення Trie продовжить зростати, стимулюючи розвиток технологій і інвестиції у відповідних секторах. Постійна еволюція та оптимізація Trie підтверджує актуальність цієї структури, створеної понад шістдесят років тому. Хоча реалізація Trie на конкретних платформах не завжди документується, їх використання для вдосконалення торгових алгоритмів, обробки фінансових даних і систем аналітики в реальному часі є ймовірним і поширеним. Основні принципи Trie — ефективне співставлення префіксів, ієрархічна організація і швидке отримання — відповідають вимогам сучасних систем, що працюють з великими даними, тому Trie залишатиметься важливим елементом технологічного середовища у майбутньому.
FAQ
Що таке Trie (префіксне дерево)? Який основний принцип?
Trie, або префіксне чи словникове дерево, — впорядкована деревоподібна структура для ефективного зберігання та пошуку рядків. Trie використовує спільні префікси для скорочення використання пам’яті. Кожен вузол містить символ і посилання на дочірні вузли, що забезпечує швидкий пошук та вставку за префіксом.
Які переваги й недоліки Trie щодо хеш-таблиць?
Trie дає змогу швидше виконувати пошук і вставку для рядкових операцій завдяки спільному використанню префіксів, зменшуючи кількість порівнянь символів. Однак Trie потребує більше пам’яті, особливо для ключів різної довжини. Trie використовує додаткову пам’ять для забезпечення ефективності часу виконання.
Як реалізувати автозаповнення та пошукові підказки за допомогою Trie?
Trie застосовує структуру префіксного дерева для швидкого співставлення префіксів із складністю O(m), де m — довжина введеного рядка. Символи зберігаються у вузлах, завершення слів позначаються у листових вузлах, що забезпечує швидке автозаповнення та пошукові підказки.
Які типові практичні сценарії використання Trie?
Trie широко застосовується для автозаповнення, перевірки й корекції правопису, виявлення та фільтрації чутливих слів, підрахунку префіксів, статистики слів, а також для ефективних бінарних запитів — наприклад, максимального XOR.
Як реалізувати базову структуру Trie?
Створіть клас вузла із хеш-таблицею та прапорцем завершення слова. Перебирайте кожне слово, послідовно вставляючи символи у Trie. Спільні префікси використовуються для оптимізації використання пам’яті.
Яка тимчасова та просторова складність Trie?
Trie має тимчасову складність O(N) для вставки та пошуку, де N — довжина рядка. Просторова складність — O(α^n), де α — потужність алфавіту.

Блокчейн просто: короткий посібник для новачків про його функціонування

Кар'єрні можливості для Core Developers у сфері розробки блокчейн

Розпочніть свою кар’єру в сфері Blockchain-розробки
Кар'єра розробника Blockchain: необхідні навички та перспективи
Основи роботи блокчейну: як він функціонує

Розвиток майбутнього Web3 для Індії: ініціативи у сфері спільнот і освіти

Що являє собою Lighter (LIGHT): це zk-Rollup перпетуальний DEX із верифікованим матчингом та надійною ліквідацією

Остерігайтеся типових шахрайських схем стейкінгу та майнінгу у сфері криптовалют

Випустили Wallet v7.3.1, додали новий режим лише для перегляду

Посібник щодо лістингу Minterest (MINTY): дата запуску та пояснення міжланцюгового DeFi-кредитування

Berachain: пояснення. Це блокчейн першого рівня на основі унікального механізму консенсусу Proof-of-Liquidity.
