Cấu trúc Trie

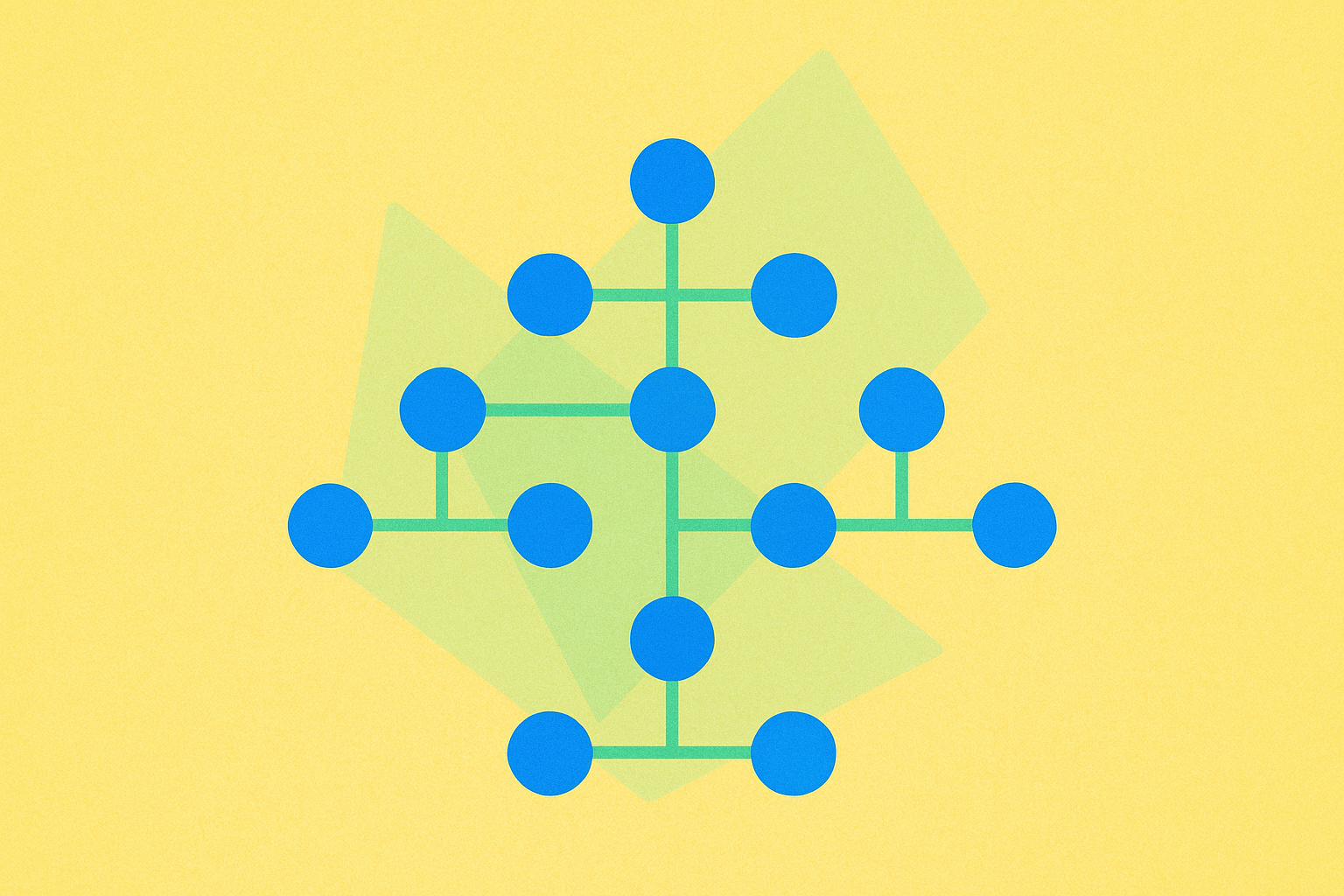
Trie, hay còn gọi là cây tiền tố, là một loại cây tìm kiếm đặc biệt được thiết kế để lưu trữ các tập hợp động hoặc bảng kết hợp mà khóa thường ở dạng chuỗi ký tự. Khác với cây tìm kiếm nhị phân, các nút trong trie không lưu trữ trực tiếp khóa của từng nút mà chính vị trí của nút trong cấu trúc cây xác định khóa tương ứng, giúp trie đặc biệt hiệu quả cho các thao tác xử lý chuỗi.
Những tiến bộ gần đây trong lĩnh vực truy xuất và lưu trữ dữ liệu đã làm nổi bật vai trò thiết yếu của các cấu trúc dữ liệu hiệu quả như trie. Chẳng hạn, tính năng gợi ý tìm kiếm tự động của Google sử dụng trie để dự đoán và hiển thị truy vấn dựa trên những ký tự đầu tiên người dùng nhập vào. Việc ứng dụng này không chỉ cải thiện trải nghiệm người dùng nhờ gợi ý tức thời mà còn tối ưu hóa quá trình tìm kiếm nhờ giảm thời gian và tài nguyên tính toán cần thiết để trả về kết quả phù hợp. Việc trie chia sẻ các tiền tố chung giữa các chuỗi giúp tối ưu bộ nhớ cho các ứng dụng xử lý tập từ vựng lớn hoặc dữ liệu chuỗi quy mô lớn.
Bối cảnh lịch sử và phát triển
Khái niệm trie lần đầu tiên được giới thiệu trong một bài báo năm 1959 của nhà khoa học máy tính người Pháp René de la Briandais, người đã đặt nền tảng cho cấu trúc dữ liệu dạng cây này. Thuật ngữ "trie" được Edward Fredkin đặt ra vào năm 1960, xuất phát từ từ "retrieval", nhấn mạnh mục đích chính của trie trong thao tác truy xuất dữ liệu. Từ khi ra đời, trie đã liên tục phát triển mạnh mẽ, chủ yếu nhờ vai trò tối ưu hóa truy vấn tìm kiếm và hỗ trợ xử lý dữ liệu lớn hiệu quả.
Cuộc cách mạng số và sự bùng nổ dữ liệu trong những thập kỷ gần đây đã biến trie từ một khái niệm học thuật thành thành phần thiết yếu của hạ tầng tính toán hiện đại. Khi các tổ chức phải xử lý lượng dữ liệu văn bản khổng lồ, các đặc tính nổi bật của trie—đặc biệt là khả năng tìm kiếm dựa trên tiền tố với thời gian tỷ lệ với độ dài khóa thay vì số lượng khóa—trở nên cực kỳ giá trị. Trie đã được mở rộng và tối ưu hóa cho nhiều ứng dụng chuyên biệt, từ kiểm tra chính tả, trò chơi chữ đến đánh chỉ mục cơ sở dữ liệu và giao thức định tuyến mạng.
Ứng dụng trong công nghệ
Trie được ứng dụng rộng rãi trong phát triển phần mềm và công nghệ thông tin nhờ cấu trúc độc đáo và hiệu quả khi xử lý dữ liệu phức tạp. Một trong những ứng dụng chính là tính năng gợi ý tự động và dự đoán văn bản, xuất hiện phổ biến ở công cụ tìm kiếm, bàn phím di động và trình soạn thảo. Các hệ thống này dựa vào trie để duyệt nhanh các khả năng hoàn thiện từ dựa trên dữ liệu nhập của người dùng, mang lại gợi ý tức thì và nâng cao hiệu quả thao tác.
Bên ngoài xử lý văn bản, trie còn giữ vai trò trọng yếu trong thuật toán định tuyến IP, hỗ trợ đối sánh nhanh địa chỉ IP với các mạng tương ứng. Trong bộ định tuyến mạng, trie giúp thực hiện thao tác đối sánh tiền tố dài nhất để xác định đường truyền tối ưu cho gói dữ liệu trên Internet. Nhờ cấu trúc này, bộ định tuyến có thể tra cứu địa chỉ với thời gian logarit theo độ dài, giảm tối đa độ trễ truyền tải.
Một lĩnh vực lớn khác là tin sinh học, nơi trie được dùng cho các tác vụ giải trình tự bộ gen và phân tích dữ liệu di truyền. Các thuật toán dựa trên trie hỗ trợ tìm kiếm nhanh trong cơ sở dữ liệu di truyền lớn, nhận diện mẫu, chuỗi con, đột biến. Tính năng này đã thúc đẩy nghiên cứu y học cá thể, sinh học tiến hóa và chẩn đoán bệnh. Trie còn ứng dụng trong xây dựng từ điển, bảng ký hiệu, thuật toán khớp chuỗi—nền tảng của hệ thống xử lý văn bản.
Tác động thị trường và đầu tư
Việc các tập đoàn công nghệ lớn ứng dụng trie đã tạo ảnh hưởng sâu rộng đến thị trường công nghệ và hoạt động đầu tư. Việc triển khai trie phổ biến giúp phát triển các giải pháp phần mềm hiệu suất cao, có khả năng xử lý dữ liệu khổng lồ nhanh chóng và chính xác hơn nhiều so với trước đây. Điều này đặc biệt quan trọng cho các công ty dữ liệu lớn, nơi tốc độ truy xuất và phân tích thông tin quyết định lợi thế cạnh tranh.
Tác động kinh tế của trie không dừng ở từng doanh nghiệp mà còn mở rộng ra toàn ngành. Đơn vị thành công trong triển khai trie vào hạ tầng dữ liệu thường giảm chi phí vận hành nhờ tối ưu hóa máy chủ và thời gian phản hồi, đồng thời nâng cao sự hài lòng, duy trì khách hàng. Những lợi ích thực tế này thúc đẩy dòng vốn đầu tư vào công nghệ ứng dụng trie, nhất là trong trí tuệ nhân tạo và học máy—nơi cấu trúc dữ liệu hiệu quả quyết định hiệu năng thuật toán.
Đầu tư vào công nghệ trie tăng mạnh những năm gần đây nhờ nhu cầu xử lý dữ liệu ngày càng hiện đại. Vốn mạo hiểm và doanh nghiệp đã rót vào startup và công ty phát triển giải pháp tìm kiếm, xử lý ngôn ngữ tự nhiên, quản lý cơ sở dữ liệu dựa trên trie. Xu hướng này cho thấy nhận thức rằng hiệu quả cấu trúc dữ liệu như trie là tài sản chiến lược quyết định vị thế thị trường trong ngành dữ liệu lớn.
Xu hướng và đổi mới tương lai
Tương lai của trie trong công nghệ rất hứa hẹn với các nghiên cứu liên tục nhằm nâng cao hiệu quả, khả năng mở rộng và thích ứng với các bài toán tính toán mới. Các cải tiến như trie nén (radix tree hoặc Patricia trie) và trie tam phân là minh chứng cho sự phát triển không ngừng của cấu trúc dữ liệu này, giúp giảm tiêu thụ bộ nhớ mà vẫn giữ hoặc tăng tốc độ tìm kiếm—phù hợp môi trường hạn chế tài nguyên như hệ thống nhúng.
Khi Internet vạn vật (IoT) mở rộng và điện toán đám mây phát triển, trie được kỳ vọng sẽ đảm nhiệm vai trò quan trọng hơn trong quản lý, truy vấn lượng dữ liệu khổng lồ do các công nghệ này sinh ra. Thiết bị IoT tạo ra dòng dữ liệu thời gian thực, nhật ký, cảm biến—tất cả đều cần cơ chế chỉ mục, truy xuất hiệu quả. Trie đặc biệt thích hợp với dữ liệu phân cấp, dựa trên tiền tố như mã thiết bị, mã vị trí.
Các ứng dụng mới trong học máy, trí tuệ nhân tạo cũng thúc đẩy trie phát triển. Các nhà nghiên cứu khai thác trie để tăng tốc thao tác mạng nơ-ron, đặc biệt trong xử lý ngôn ngữ tự nhiên nơi quản lý từ vựng và tra cứu embedding là điểm nghẽn. Việc tích hợp trie với phần cứng mới như bộ nhớ không mất dữ liệu và bộ xử lý chuyên biệt hứa hẹn đột phá hiệu năng. Những đổi mới này có thể tạo ra bước ngoặt về công nghệ lưu trữ, tìm kiếm, phân tích dữ liệu đa ngành.
Tổng kết
Tóm lại, trie là cấu trúc dữ liệu mạnh mẽ, đa năng trong điện toán hiện đại với ứng dụng rộng rãi trong nhiều ngành nhằm tối ưu hóa truy xuất dữ liệu và hiệu suất hệ thống. Khả năng xử lý hiệu quả tập dữ liệu lớn với khóa chuỗi phức tạp khiến trie không thể thiếu trong công cụ tìm kiếm, định tuyến mạng, tin sinh học. Đặc thù chia sẻ tiền tố giúp trie tiết kiệm bộ nhớ, tăng tốc độ tra cứu—những giá trị ngày càng lớn khi dữ liệu bùng nổ.
Khi dữ liệu tiếp tục tăng nhanh cả về số lượng và độ phức tạp, vai trò của trie sẽ ngày càng lớn, thúc đẩy phát triển công nghệ và dòng vốn vào các lĩnh vực liên quan. Sự tiến hóa liên tục của các biến thể trie thể hiện giá trị trường tồn của cấu trúc dữ liệu này, dù đã ra đời hơn sáu thập kỷ. Dù trie không luôn được ghi nhận cụ thể trên từng nền tảng, nhưng ứng dụng của nó trong nâng cấp thuật toán giao dịch, xử lý dữ liệu tài chính, phân tích thời gian thực ngày càng phổ biến. Các nguyên lý cốt lõi của trie—đối sánh tiền tố hiệu quả, phân cấp, truy xuất nhanh—phù hợp hoàn hảo với nhu cầu ứng dụng dữ liệu hiện đại, đảm bảo vị thế quan trọng cho trie trong tương lai công nghệ.
Câu hỏi thường gặp
Trie (Cây tiền tố) là gì? Nguyên lý cơ bản của nó?
Trie, còn gọi là cây tiền tố hoặc cây từ điển, là cấu trúc cây có thứ tự giúp lưu trữ, truy xuất chuỗi hiệu quả. Trie chia sẻ các tiền tố chung giữa chuỗi để tiết kiệm bộ nhớ. Mỗi nút chứa một ký tự và liên kết tới các nút con, cho phép tìm kiếm, chèn nhanh theo tiền tố.
Ưu điểm và nhược điểm của Trie so với bảng băm?
Trie cho phép truy xuất, chèn chuỗi nhanh nhờ chia sẻ tiền tố—giảm so sánh ký tự. Tuy nhiên, trie tiêu tốn nhiều bộ nhớ hơn, nhất là với khóa biến độ dài. Trie đánh đổi bộ nhớ lấy tốc độ.
Triển khai gợi ý tự động, đề xuất tìm kiếm bằng Trie như thế nào?
Trie dùng cấu trúc cây tiền tố để khớp tiền tố nhanh với độ phức tạp O(m), m là độ dài chuỗi nhập. Lưu ký tự trong các nút, đánh dấu kết thúc từ ở nút lá—giúp gợi ý tự động, tìm kiếm nhanh.
Trie thường được ứng dụng trong những trường hợp nào?
Trie ứng dụng rộng rãi trong gợi ý tự động, kiểm tra/sửa chính tả, phát hiện-lọc từ nhạy cảm, đếm tiền tố, thống kê từ và các truy vấn nhị phân hiệu quả như thao tác XOR lớn nhất.
Cách xây dựng Trie cơ bản?
Tạo lớp nút cùng bảng băm và cờ đánh dấu kết thúc từ. Duyệt từng từ, tuần tự chèn ký tự vào Trie, chia sẻ tiền tố sẵn có để tối ưu bộ nhớ.
Độ phức tạp thời gian và không gian của Trie?
Trie có độ phức tạp thời gian O(N) với thao tác chèn, tìm kiếm, N là độ dài chuỗi; độ phức tạp không gian O(α^n), α là kích thước bảng ký tự.

Giải Mã Blockchain: Hướng Dẫn Nhập Môn Về Cơ Chế Hoạt Động

Khám phá các lựa chọn nghề nghiệp trong ngành phát triển Blockchain dành cho Core Developers

Khởi đầu sự nghiệp phát triển Blockchain chuyên nghiệp

Khám phá sự nghiệp Blockchain Developer: Kỹ năng và cơ hội
Kiến Thức Cơ Bản Về Blockchain: Nguyên Lý Hoạt Động

Thúc đẩy sức mạnh cho tương lai Web3 của Ấn Độ: Các sáng kiến về cộng đồng và giáo dục

Hướng Dẫn Phân Tích Dữ Liệu On-Chain XVS: Đánh Giá Địa Chỉ Hoạt Động, Phân Bổ Cá Voi và Các Xu Hướng Giao Dịch Trong Năm 2026

Những rủi ro bảo mật lớn nhất đối với tiền mã hóa cùng các điểm yếu trong hợp đồng thông minh dự kiến nổi bật vào năm 2026 là gì?

Biến động giá của LMWR là gì và mối tương quan giữa LMWR với diễn biến của BTC và ETH trong năm 2026 như thế nào?

Pi Coin là gì? Hướng dẫn toàn diện về giá trị, giá cả và cách giao dịch Pi Coin

Các rủi ro liên quan đến quy định pháp lý và việc tuân thủ của Pump.fun trong năm 2025 bao gồm những yếu tố nào?
