Trie(字典树)

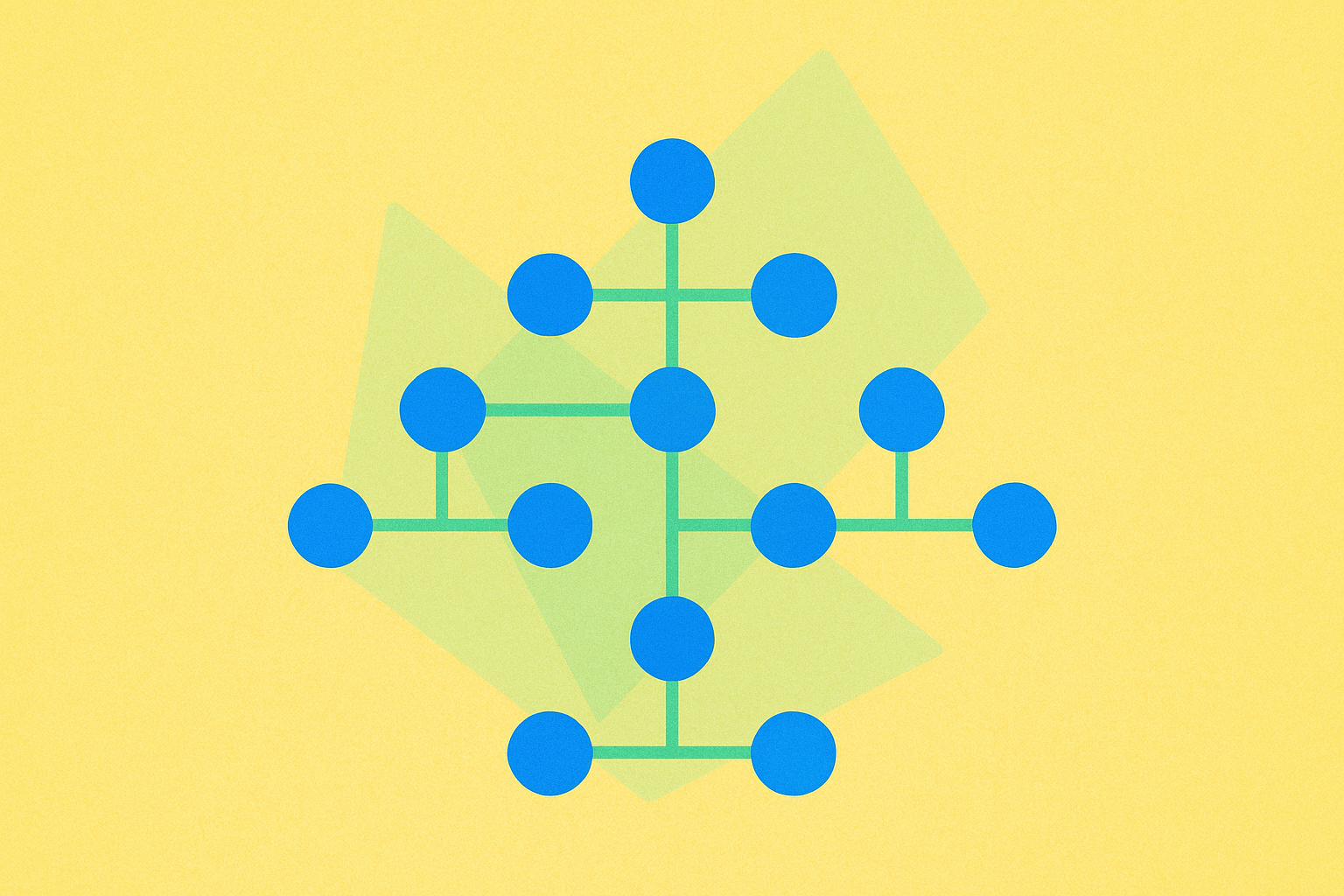
Trie,又称前缀树,是一种专门用于存储动态集合或关联数组的搜索树结构,键通常是字符串。不同于二叉搜索树,Trie 的节点并不直接保存与该节点关联的键值,而是通过节点在树结构中的位置确定其对应键,因此在处理字符串相关操作时表现出极高的效率。
近年来,数据检索与存储技术的进步进一步凸显了 Trie 等高效数据结构的重要性。例如,Google 的自动补全功能正是基于 Trie 数据结构,通过分析用户输入的起始字符,预测并展示搜索建议。这种应用不仅显著提升了用户体验,还有效优化了搜索流程,降低了查询所需的时间和计算资源。Trie 能够在存储字符串时复用公共前缀,使其在大规模词汇或庞大字符串数据集场景下极为节省内存。
历史背景与发展
Trie 的基本思想最早由法国计算机科学家 René de la Briandais 于 1959 年提出,首次系统阐述了该类树形数据结构的原理。1960 年,Edward Fredkin 创造了“Trie”这一术语,取自“retrieval”,强调其在数据检索中的核心作用。自诞生以来,Trie 不断演进,并凭借优化查询和高效处理大规模数据集的能力,成为关键的数据结构之一。
随着数字化进程加速和数据量的爆炸式增长,Trie 已从学术理论转变为现代计算基础设施的重要组成部分。企业在应对海量文本数据时,Trie 依靠按搜索键长度而非存储键数量进行前缀检索的特性,展现出极高的价值。如今,Trie 被广泛适用于各种专业场景,包括拼写检查、文字游戏、数据库索引及网络路由协议等。
技术领域的应用
凭借其独特的数据结构和卓越的处理效率,Trie 在软件开发和信息技术领域得到了广泛应用。自动补全和文本预测是其典型场景,这些功能已成为现代搜索引擎、移动输入法和文本编辑器的标配。相关系统通过 Trie 能够依据用户输入快速遍历所有可能的词语补全,实时提供建议,大幅提升用户效率。
在文本处理之外,Trie 还是实现 IP 路由算法的核心数据结构,支持将 IP 地址与目标网络的高效匹配。在网络路由器中,Trie 实现了最长前缀匹配,成为决定数据包在互联网中最优路径的基础。路由器利用 Trie 可在与地址长度相关的对数时间内完成查找,最大程度减少数据转发延迟。
生物信息学领域同样大量采用 Trie,实现高效的基因组测序与分析。研究者借助基于 Trie 的算法,能够在庞大基因数据库中快速查找和定位特定序列、模式或突变。这一能力极大加速了个性化医疗、进化生物学及疾病诊断等前沿研究。同时,Trie 也广泛应用于字典、符号表以及多类字符串匹配算法,为文本处理系统提供底层支撑。
市场影响与投资
主流科技公司大规模采用 Trie 数据结构,极大推动了整个技术市场和投资格局的变革。得益于 Trie 的广泛应用,软件系统能够以前所未有的速度和精度处理海量数据,尤其在大数据领域,数据检索和分析能力已成为企业核心竞争力的重要来源。
Trie 优化带来的经济效益不仅体现在企业自身,更影响到整个行业生态。通过在基础设施中高效运用 Trie,组织能够降低服务器资源消耗和系统响应时间,从而减少运营成本,提升客户满意度和留存率。这些实际收益吸引了资本市场对采用 Trie 技术的强烈关注,特别是在高效数据结构对算法性能至关重要的人工智能和机器学习平台领域。
近年来,随着对高效数据处理能力需求的不断提升,Trie 技术相关投资持续增长。风险投资和企业资金加速流向依赖优化 Trie 实现的搜索系统、自然语言处理工具和数据库管理方案的创新企业和成熟厂商。这一趋势反映出高效数据结构如 Trie 已成为决定数据密集型产业市场地位的重要战略资产,而非单纯的技术细节。
未来趋势与创新
Trie 在技术领域的未来发展前景极为广阔,当前研究聚焦于提升其效率、可扩展性及对新兴计算场景的适用性。压缩 Trie(也称 Radix Tree 或 Patricia Trie)、三分搜索 Trie 等创新结构,进一步降低内存消耗,同时保持或提升检索性能,非常适合内存受限和嵌入式系统环境。
随着物联网(IoT)和云计算技术的持续发展,Trie 有望在管理和查询这些技术所产生的海量数据中扮演更加关键的角色。IoT 设备不断生成时序数据、日志和传感器信息,这些都对高效索引和检索机制提出了更高要求。Trie 结构非常适合处理 IoT 数据的层级化和前缀特性,从设备编号到地理编码均可高效支持。
机器学习和人工智能领域的新兴应用也在推动 Trie 的持续创新。研究人员探索将 Trie 应用于神经网络操作加速,尤其在自然语言处理任务中,能够有效提升词汇管理和词向量检索的性能。此外,将 Trie 与新型硬件架构如非易失性存储和专用处理器结合,有望释放更大潜力。这些创新有望带来数据处理技术的突破,进一步变革多领域的信息存储、检索与分析方式。
总结
综上所述,Trie 数据结构作为现代计算的重要工具,凭借高效处理复杂字符串键的大型数据集能力,在搜索引擎、网络路由和生物信息学等领域扮演着不可替代的角色。其通过复用存储键的公共前缀,实现了内存利用率高、查找速度快等优势,随着数据量持续增长,这些特性愈发重要。
随着数据体量和复杂度的不断增加,Trie 的价值也将持续提升,进一步推动相关技术领域的发展和投资。Trie 及其变体的演进充分证明了其诞生六十余年来的持久活力。尽管各平台的 Trie 实现方式未必详尽公开,但其在优化交易算法、金融数据处理及实时分析系统中的广泛应用已成趋势。Trie 的高效前缀匹配、分层组织和快速检索等核心原理,完美契合现代数据密集型场景的需求,确保其未来在技术格局中的持续地位。
常见问题
什么是 Trie(前缀树)?其基本原理是什么?
Trie(前缀树或字典树)是一种有序树结构,用于高效存储和检索字符串。它通过共享字符串的公共前缀减少存储空间消耗,每个节点包含一个字符并引用子节点,实现高效的前缀查找和插入。
Trie 相比哈希表有哪些优缺点?
Trie 利用前缀共享,在字符串操作中实现更快的查找和插入,减少字符比较次数,但其内存开销较大,尤其在处理变长键时更为明显。整体而言,Trie 是以空间换取时间效率。
如何利用 Trie 实现自动补全和搜索建议?
Trie 通过前缀树结构,能以 O(m) 时间复杂度(m 为输入字符串长度)快速匹配前缀。将字符存储在节点中,在叶节点标记单词结尾,实现高效的自动补全和搜索建议功能。
Trie 在实际应用中有哪些常见场景?
Trie 广泛用于自动补全、拼写检查与纠错、敏感词检测与过滤、前缀计数、词频统计,以及如最大异或运算等高效二进制查询。
如何实现一个基础的 Trie 数据结构?
可创建包含哈希表和单词结尾标记的节点类,遍历每个单词,依次将字符插入 Trie,共享已有前缀以优化存储。
Trie 的时间复杂度和空间复杂度是多少?
Trie 的插入与查找操作时间复杂度为 O(N),N 为字符串长度。空间复杂度为 O(α^n),其中 α 是字符集大小。

區塊鏈入門指南:新手如何理解其運作原理

核心开发者在区块链开发领域的职业路径探索

开启区块链开发职业新篇章

区块链开发者职业路径探析:必备技能与发展机遇
區塊鏈運作基礎:運作原理

赋能印度Web3未来:社区建设与教育计划
埃隆·马斯克持有哪些加密货币

深度探讨市场暴跌后值得关注的热门加密货币预售项目

Football.Fun 是什么?一款以真实比赛为核心的网页足球管理游戏

Hamster Kombat 每日密码代码指引

Hamster Kombat 每日加密口令
