Trie

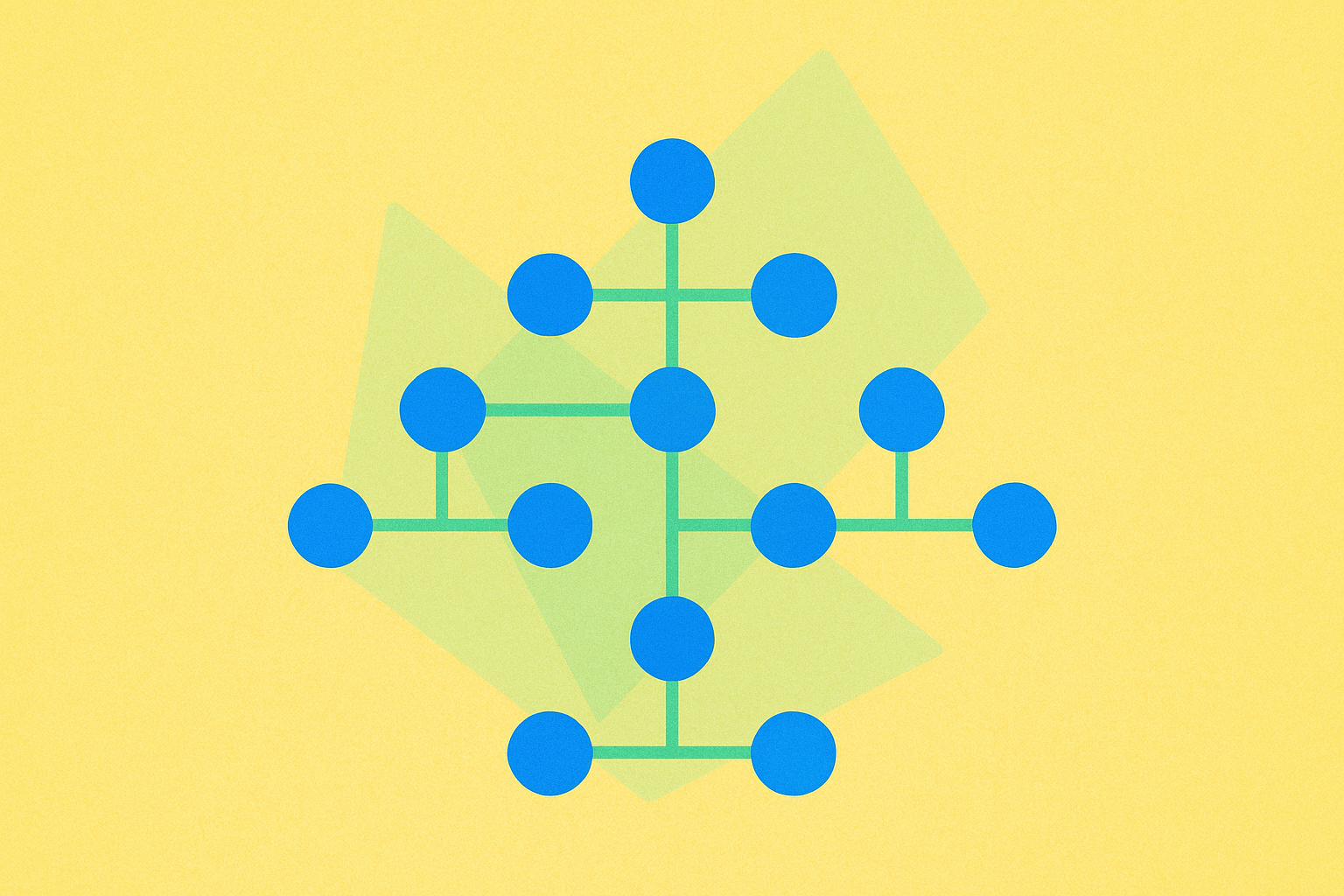
Un trie, ou arbre préfixe, est une structure de recherche spécialisée permettant de stocker des ensembles dynamiques ou des tableaux associatifs dont les clés sont généralement des chaînes de caractères. Contrairement aux arbres de recherche binaires, les nœuds d’un trie ne contiennent pas directement la clé associée ; c’est la position du nœud dans l’arbre qui définit sa clé, ce qui rend cette structure particulièrement efficace pour les opérations sur les chaînes de caractères.
Les progrès récents en matière de récupération et de stockage des données soulignent l’importance stratégique des structures de données performantes telles que les tries. Par exemple, la fonction d’autocomplétion de Google repose sur les tries pour prédire et afficher les requêtes en fonction des premiers caractères saisis. Cette approche améliore l’expérience utilisateur grâce à des suggestions instantanées tout en optimisant le processus de recherche, réduisant ainsi le temps et les ressources informatiques nécessaires pour fournir des résultats pertinents. La capacité du trie à mutualiser les préfixes communs des chaînes stockées le rend particulièrement économique en mémoire pour les applications à grand vocabulaire ou à jeux de données volumineux.
Contexte historique et évolution
Le concept de trie a été présenté pour la première fois en 1959 par l’informaticien français René de la Briandais, qui en a posé les bases fondamentales. Le terme « trie » a ensuite été proposé par Edward Fredkin en 1960, dérivé du mot « retrieval » afin de souligner sa vocation dans les opérations de recherche et de récupération de données. Depuis son origine, le trie a connu une évolution majeure, portée par son rôle clé dans l’optimisation des requêtes et la gestion efficace de vastes ensembles de données.
La révolution numérique et l’explosion du volume de données au cours des dernières décennies ont transformé le trie d’un concept académique à un pilier de l’infrastructure informatique moderne. Face à l’accroissement massif des données textuelles, les propriétés distinctives du trie—en particulier la recherche par préfixe en temps proportionnel à la longueur de la clé plutôt qu’au nombre de clés stockées—sont de plus en plus appréciées. Cela a conduit à l’adaptation et à l’optimisation des tries pour des applications spécialisées, comme les correcteurs orthographiques, les jeux de lettres, l’indexation de bases de données ou le routage réseau.
Applications technologiques
Les tries occupent une place centrale dans le développement logiciel et les technologies de l’information grâce à leur structure unique et leur efficacité dans la gestion de grands ensembles de données. Ils sont largement utilisés dans les fonctionnalités d’autocomplétion et de prédiction de texte, omniprésentes dans les moteurs de recherche, les claviers mobiles et les éditeurs de texte. Ces systèmes exploitent les tries pour explorer rapidement les complétions possibles à partir de la saisie utilisateur, offrant des suggestions en temps réel et améliorant la productivité.
Outre le traitement de texte, les tries sont essentiels dans les algorithmes de routage IP, facilitant l’association rapide des adresses IP à leurs réseaux. Dans les routeurs, ils permettent un appariement efficace du préfixe le plus long, déterminant le chemin optimal des paquets de données sur Internet. Cette organisation autorise des recherches en temps logarithmique selon la longueur de l’adresse, garantissant une faible latence lors du transfert de paquets.
En bioinformatique également, les tries sont utilisés pour le séquençage et l’analyse génomique efficace. Les chercheurs s’appuient sur des algorithmes basés sur les tries pour scruter rapidement de vastes ensembles de données génétiques, identifier des motifs, des sous-séquences ou des mutations. Cette rapidité de localisation de séquences ADN spécifiques dans d’immenses bases de données génomiques accélère les progrès en médecine personnalisée, biologie évolutive et diagnostic. Les tries servent aussi à la gestion de dictionnaires, de tables de symboles et à divers algorithmes de recherche de chaînes, qui constituent l’ossature des systèmes de traitement de texte.
Impact sur le marché et investissements
L’intégration des structures trie par les grandes entreprises technologiques a profondément influencé le marché et le paysage de l’investissement. Leur déploiement généralisé a permis le développement de solutions logicielles plus rapides et plus performantes, capables de traiter d’énormes volumes de données avec une précision et une rapidité accrues. Ces gains d’efficacité sont particulièrement décisifs pour les acteurs du big data, où la rapidité de récupération et d’analyse de l’information constitue un réel avantage concurrentiel.
Les retombées économiques des optimisations basées sur les tries dépassent le cadre des entreprises pour impacter des secteurs entiers. Les organisations qui maîtrisent les tries constatent souvent une baisse des coûts opérationnels grâce à la réduction des besoins en serveurs et à l’amélioration des temps de réponse, ce qui se traduit par une meilleure satisfaction et fidélisation des clients. Ces bénéfices concrets stimulent l’investissement dans les technologies utilisant les tries, notamment dans l’intelligence artificielle et l’apprentissage automatique, où les structures de données optimisées sont essentielles à la performance des algorithmes.
L’investissement dans les technologies à base de trie a fortement progressé ces dernières années, porté par la demande croissante en outils de traitement de données avancés. Le capital-risque et les financements d’entreprise soutiennent aussi bien les startups que les sociétés établies développant des moteurs de recherche, des solutions de traitement du langage naturel et des systèmes de gestion de bases de données reposant sur des implémentations optimisées de tries. Cette dynamique traduit la reconnaissance que l’efficacité des structures de données comme les tries est un enjeu stratégique pour le leadership sur les marchés intensifs en données.
Tendances et innovations à venir
L’avenir des tries s’annonce particulièrement dynamique, avec des recherches soutenues pour accroître leur efficacité, leur scalabilité et leur adaptation aux nouveaux défis informatiques. Des innovations telles que les tries compressés (radix trees ou Patricia tries) et les tries de recherche ternaires illustrent l’évolution continue de cette structure, qui répond aux exigences des systèmes modernes. Ces variantes permettent de réduire la consommation mémoire tout en maintenant, voire en améliorant, les performances de recherche, ce qui les rend adaptées aux environnements contraints et aux systèmes embarqués.
Avec l’essor de l’Internet des objets (IoT) et la sophistication croissante du cloud computing, les tries devraient jouer un rôle clé dans la gestion et l’indexation des flux massifs de données générés. Les dispositifs IoT produisent des séries temporelles, des journaux et des relevés de capteurs qui exigent des mécanismes d’indexation et de récupération performants. Les tries conviennent particulièrement à la nature hiérarchique et préfixée des formats de données IoT, des identifiants d’appareils aux codes de localisation.
Les avancées en intelligence artificielle et en apprentissage automatique stimulent également l’innovation autour des tries. Les chercheurs examinent comment les tries peuvent accélérer les opérations des réseaux neuronaux, notamment dans le traitement du langage naturel où la gestion des vocabulaires et la recherche d’embeddings constituent un défi de performance. De plus, l’intégration des tries avec des architectures matérielles innovantes, telles que la mémoire non volatile et les unités de traitement spécialisées, ouvre la voie à de nouveaux gains de performance. Ces évolutions pourraient déboucher sur des ruptures technologiques majeures dans la gestion et le traitement des données, transformant la manière de stocker, rechercher et analyser l’information dans de nombreux domaines.
Résumé
En définitive, le trie est une structure de données puissante et polyvalente, essentielle à l’informatique moderne et largement utilisée dans de nombreux secteurs pour améliorer la recherche d’information et l’efficacité des systèmes. Sa capacité à traiter efficacement de grands ensembles de données dotés de clés complexes en fait un outil indispensable dans les moteurs de recherche, le routage réseau et la bioinformatique. L’atout majeur du trie réside dans le partage des préfixes communs entre les clés stockées, garantissant à la fois une économie de mémoire et des temps de recherche réduits—des qualités de plus en plus précieuses à mesure que les volumes de données progressent.
Avec l’évolution constante du volume et de la complexité des données, l’importance des tries ne cesse de croître, stimulant le développement technologique et les investissements dans les secteurs concernés. L’adaptation continue des variantes et optimisations démontre la pertinence durable de cette structure, conçue il y a plus de soixante ans. Si leur implémentation sur certaines plateformes n’est pas toujours explicitement documentée, leur utilisation pour améliorer les algorithmes de trading, le traitement des données financières et les systèmes d’analytique en temps réel est hautement probable et désormais fréquente. Les principes fondamentaux du trie—appariement efficace des préfixes, organisation hiérarchique et récupération rapide—répondent parfaitement aux exigences des applications modernes intensives en données, assurant sa place dans le paysage technologique pour les années à venir.
FAQ
Qu’est-ce qu’un Trie (arbre préfixe) ? Quel est son principe de base ?
Un trie, également appelé arbre préfixe ou arbre dictionnaire, est une structure arborescente ordonnée conçue pour le stockage et la recherche efficaces de chaînes de caractères. Il mutualise les préfixes communs entre les chaînes afin de réduire l’espace mémoire. Chaque nœud porte un caractère et des références vers les nœuds enfants, permettant des recherches et insertions rapides par préfixe.
Quels sont les avantages et les limites du Trie par rapport aux tables de hachage ?
Le trie permet des recherches et insertions rapides sur les chaînes grâce au partage des préfixes, ce qui réduit les comparaisons de caractères. Toutefois, il requiert plus de mémoire, surtout pour les clés de longueur variable. Ce compromis favorise la rapidité d’accès au détriment de l’espace mémoire.
Comment implémenter l’autocomplétion et les suggestions de recherche avec un Trie ?
Un trie exploite sa structure en arbre préfixé pour associer rapidement les préfixes avec une complexité de O(m), où m est la longueur de la chaîne saisie. Les caractères sont stockés dans les nœuds et la fin des mots est signalée aux feuilles, ce qui permet une autocomplétion et des suggestions rapides.
Quels sont les principaux cas d’usage du Trie en pratique ?
Le trie est utilisé dans l’autocomplétion, la correction et la vérification orthographique, la détection et le filtrage de mots sensibles, le comptage de préfixes, les statistiques lexicales et les requêtes binaires rapides telles que les opérations de XOR maximal.
Comment réaliser une structure de données Trie élémentaire ?
Il convient de créer une classe de nœud avec une table de hachage et un marqueur de fin de mot. Parcourez chaque mot et insérez les caractères de façon séquentielle dans le trie, en partageant les préfixes existants pour optimiser l’espace.
Quelles sont les complexités temporelle et spatiale du Trie ?
Le trie présente une complexité temporelle de O(N) pour l’insertion et la recherche, où N est la longueur de la chaîne. Sa complexité spatiale est de O(α^n), α étant la taille de l’alphabet.

La blockchain simplifiée : guide du débutant pour comprendre son fonctionnement

Explorer les opportunités de carrière dans le développement blockchain pour les développeurs core

Donnez un nouvel élan à votre carrière dans le développement Blockchain

Envisager une carrière de développeur Blockchain : compétences requises et perspectives
Principes fondamentaux de la blockchain : fonctionnement

Renforcer l’avenir du Web3 en Inde : initiatives communautaires et éducatives

Analyse des données on-chain dans la crypto : explication des adresses actives, des mouvements de whales et des tendances des transactions

Qu'est-ce que le token Venus XVS : présentation de la logique du whitepaper, des cas d'utilisation et des innovations techniques

Comment analyser les données on-chain de XVS : adresses actives, répartition des whales et tendances des transactions en 2026

Quels sont les principaux risques de sécurité associés aux crypto-monnaies et les vulnérabilités des smart contracts en 2026 ?

Qu'entend-on par volatilité du prix de LMWR et comment cette volatilité s’articule-t-elle avec les variations de BTC et ETH en 2026 ?
